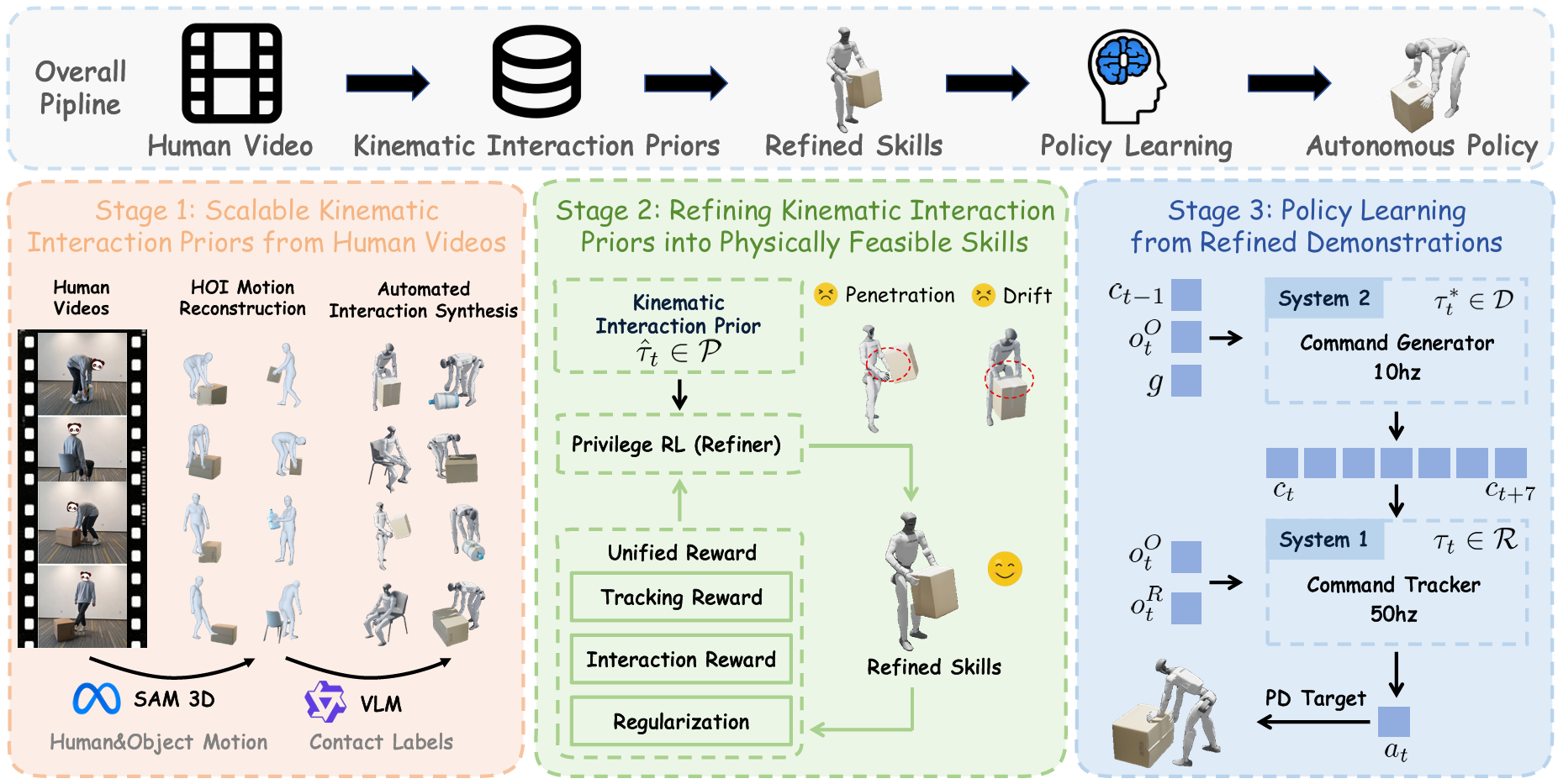
Building humanoid robots that perform generalizable whole-body loco-manipulation in the real world remains a fundamental challenge: existing approaches either rely on heavy task-specific reward engineering, rigidly replay reference motions that fail to generalize, or depend on costly teleoperation that limits scalability.
While human videos capture diverse human behaviors, the motion priors inferred from them are inherently imperfect, suffering from occlusion, contact artifacts, and retargeting errors that render them unsuitable for direct policy learning.
To this end, we present SUGAR, a data-driven framework that converts diverse human videos into deployable humanoid loco-manipulation skills, without any task-specific reward engineering or reference-motion conditioning at inference.